Power Query : Recherche Approximative

Comment effectuer une recherche avec une correspondance approximative dans Power Query ?
Les cas d’usage en Supply Chain sont multiples : taille de lot, emplacement d’entrepôt, planification des tournées de livraison, tarification par palier, réassort et seuils de commande…
Le premier réflexe est de jouer avec les paramètres de la fonction Fusionner. Malheureusement, aucune des possibilités offertes ne permet de retourner le prochain élément plus grand si aucune correspondance exacte n’est trouvée.
Si la fonction n’existe pas alors il suffit de la créer !
L’occasion de découvrir les incroyables possibilités qu’offre la manipulation des tables et des listes dans des colonnes personnalisées.
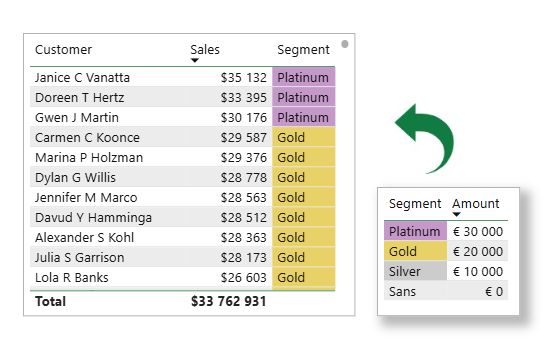
L’exemple que j’ai choisi consiste à grouper les clients en segment (Platinum, Gold, Silver) en fonction de leurs achats de l’année précédente. En quelques étapes, nous allons enrichir la formule d’une colonne personnalisée pour obtenir le résultat souhaité.
Récupérer la table Segments pour chaque ligne de la table Customer
Filtrer cette table en fonction du montant des ventes du client (Amount)
Obtenir la liste filtrée des segments correspondants (Segment)
Récupérer le dernier segment de la liste
Résoudre les problèmes de performance
Pour ce faire, nous allons utiliser plusieurs fonctions très intéressantes du langage M
Table.SelectRows() pour filtrer une table à partir d’une condition
List.Last() pour récupérer le dernier élément d’une liste
Table.buffer() pour mettre en mémoire la table de recherche et gagner en performance
En cinq étapes, je vous montre comment, à l’aide d’une seule formule, vous allez pouvoir récupérer pour chaque ligne la valeur approximative recherchée. Et surtout, d’obtenir le résultat quasi instantanément, même avec une table contenant plus de 100 000 lignes !
Importer les données dans Power Query
La première étape consiste à charger les données :
La table de recherche (Segment)

Et la table des clients (Customer)

Récupérer la table Segments dans une nouvelle colonne
Notre objectif est de trouver pour chaque client le segment (Segment[Segment]) qui correspond au montant des ventes (Customer[Amount]).
Nous allons construire pas à pas la fonction qui va permettre d’obtenir le résultat attendu.
Pour commencer, nous allons simplement ajouter une colonne personnalisée qui va récupérer la totalité de la table Segment pour chaque ligne

Dans le menu Ajouter une colonne, cliquer sur Ajouter une colonne personnalisée
Dans la fenêtre Colonne personnalisée, nommer la colonne Segment et saisir Segment dans la formule. Cliquer sur OK
Renommer l’étape : Segment ajoutée

La table Segment est ajoutée à chaque ligne de la table Customer
Filtrer la table Segment en fonction du montant
L’étape suivante est la plus importante. Elle consiste à filtrer la table Segment ajoutée à chaque ligne de la table Customer en fonction du montant des ventes du client.
Pour cela, nous allons modifier la formule de la colonne Segment de la manière suivante :
= Table.SelectRows(Segment, (X) => X[Amount] <= [Amount])
Explications :
Table.SelectRows(table a stable, condition as function) : c’est la fonction principale. Elle nous sert à filtrer les lignes de la table Segment sur la base d’une condition
(X) => X[Amount] <= [Amount] : C’est la condition qui est évaluée à chaque ligne. Elle teste si la valeur Amount de cette ligne (X) => X[Amount] est inférieure ou égale à une des valeurs de la colonne Amount de la table Segment [Amount].

La table Segment est maintenant filtrée en fonction de la valeur de la colonne Amount
Nous allons à nouveau modifier la formule pour récupérer uniquement la colonne Segment
= Table.SelectRows(Segment, (X) => X[Amount] <= [Amount])[Segment]

La colonne Segment affiche maintenant les valeurs de segment.
Récupérer la dernière valeur de la liste des segments
La dernière étape va consister à ne garder que la dernière valeur de notre liste de segments. C’est-à-dire le prochain élément plus grand si aucune correspondance exacte n’est trouvée.
Une fois encore, nous allons modifier la formule et filtrer le résultat en utilisant la fonction List.Last().
= List.Last(Table.SelectRows(Mentions, (X) => X[Note] <= [Note])[Segment])

La colonne Segment affiche pour chaque ligne le segment correspondant au montant du client.
Résoudre les problèmes de performance
Oui mais ce qui fonctionne bien pour quelques dizaines voire centaines de lignes commence à poser des problèmes de performance quand on atteint plusieurs milliers de lignes à traiter. C'est un peu comme si on exécute une fusion de requête pour chaque ligne plutôt qu'une fusion pour la table entière.
Alors comment remédier au problème de performance lorsque le nombre de lignes augmente fortement ?
L’occasion de découvrir et de tester la fonction Table.Buffer(). Cette fonction permet de placer la table de recherche en mémoire tampon (et donc, d’éviter de la charger à chaque exécution de la fonction)
L’astuce consiste à ajouter une étape pour mettre en mémoire la table Segment avant d’appliquer la fonction
= Table.Buffer(Segment)

Sélectionner l’étape qui précède l’étape d’ajout de la colonne Segment : Changed Type
Clic droit et sélectionner Insérer l’étape d’après
Renommer l’étape : BufferSegment
Saisir dans la barre de formule : Table.Buffer(Segment)
Sélectionner l’étape d’ajout de la colonne Segment : Segment ajoutée
Power Query affiche une erreur. En effet, la formule fait maintenant référence à l’étape que nous avons ajoutée : BufferSegment.

Pour corriger l’erreur, il suffit, dans la barre de formule, de remplacer BufferSegment par le nom de l’étape qui contient notre table des clients : #"Changed Type"
Enfin, pour que notre colonne personnalisée utilise la table Segment mis en mémoire grâce à la fonction Table.Buffer(), il nous reste à modifier une dernière fois la formule
List.Last(Table.SelectRows(BufferSegment, (X) => X[Amount] <= [Amount])[Segment])
Le résultat est tout simplement bluffant :
Sans buffer, la requête met prêt de 40s pour exécuter les 100 000 lignes
Avec buffer, la même requête tombe à moins de 5s !!!

* L’utilisation de cette fonction peut dans certains cas, ralentir l’exécution de vos requêtes en raison du coût supplémentaire lié à la lecture de toutes les données et à leur stockage en mémoire. Autre limite, utiliser cette fonction empêche le Query Folding.

Dans cet exemple, nous avons réalisé une recherche approximative sur une table de 100 000 lignes.
En 5 étapes simples , nous avons construit une formule qui, à chaque ligne, filtre la table de recherche pour ne garder que la dernière valeur, c’est-à-dire le prochain élément plus grand si aucune correspondance exacte n’est trouvée.
Pour aller plus loin …
Les liens pour plus détails sur les fonctions utilisés dans cet exemple
Table.SelectRows : https://powerquery.how/table-selectrows/
List.Last : https://powerquery.how/list-last/
Table.Buffer : https://powerquery.how/table-buffer/
Cet exemple simple démontre la puissance du langage M et la facilité offerte par l’interface de Power Query pour construire, pas à pas, des formules sophistiquées.
Et rappelez-vous. C’est Power Query : si ça fonctionne dans Excel, ça fonctionne à l’identique dans Power BI. Un simple copier-coller de la requête et le tour est joué !